

The Rise of Cloud AI in Scalable Application Development
AI is no longer just a buzzword; it’s now embedded in everything from mobile apps and enterprise systems to wearables and IoT devices. As demand for intelligent features such as personalization, automation, and predictive analytics grows, so does the need for scalable, reliable, and cost-effective ways to deploy AI. That’s where cloud AI services come in.
Cloud AI services offer developers, product teams, and businesses the ability to integrate powerful machine learning and AI capabilities without the overhead of building complex infrastructure or managing massive datasets from scratch. Whether you’re building chatbots, recommendation engines, fraud detection systems, or image recognition features, these services help you scale quickly and securely.
Let’s see some statistics now.
Cloud AI Market Growth Snapshot
The global cloud AI market size was valued at USD 78.36 billion in 2024. It is projected to grow from USD 102.09 billion in 2025 to a staggering USD 589.22 billion by 2032, exhibiting a compound annual growth rate (CAGR) of 28.5% during the forecast period. In 2024, North America led the global market, accounting for 35.38% of the total share.
This rapid growth highlights the increasing adoption of cloud AI solutions as enterprises seek scalable, intelligent technologies to drive innovation and operational efficiency.
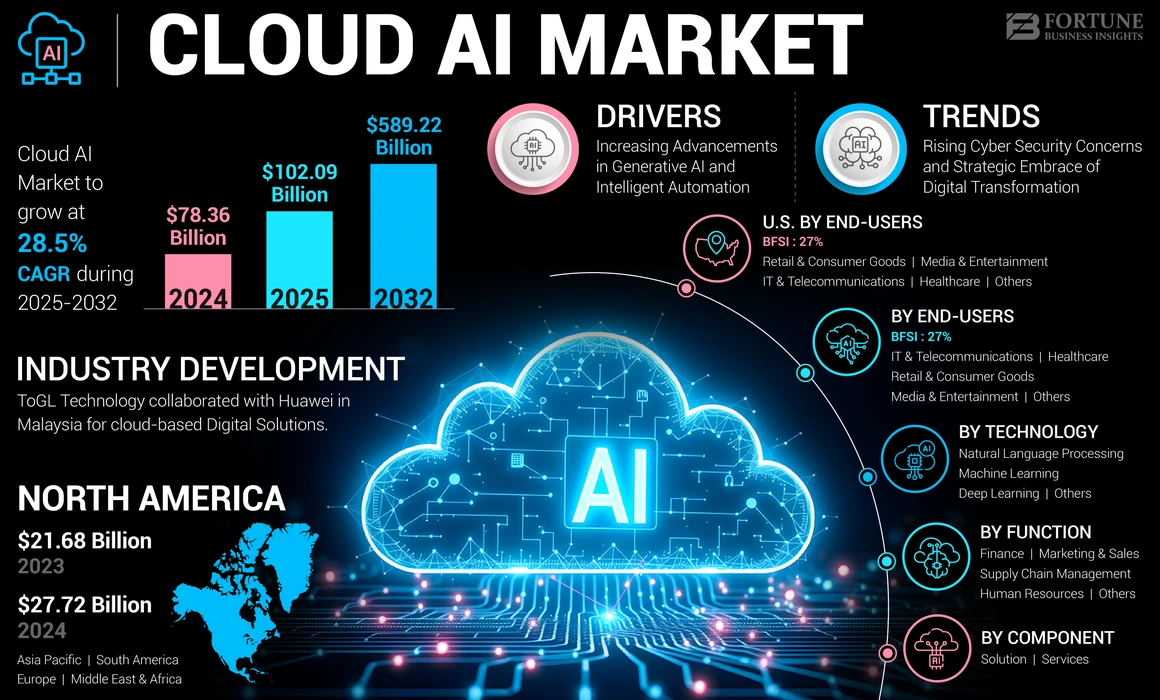
Source: Fortune Business Insights
Today, leading platforms such as Google Cloud AI, AWS AI Services, and Azure AI allow teams to access pre-trained models, run custom AI pipelines, and deploy globally accessible, production-ready AI services with just a few lines of code.
But here’s the catch: choosing the right cloud AI services is just the first step. What really matters is how you implement and scale those services into applications that serve millions, reliably, cost-effectively, and securely.
Let’s find more details to gain insights into critical technical decisions, explore scalable deployment architectures, understand real-world challenges, and discover how to effectively implement cloud AI solutions.
You’ll also learn how Emorphis can help you move faster, scale smarter, and deliver intelligent outcomes with purpose-built cloud AI strategies.
What Makes an AI Application Scalable?
As you begin leveraging cloud AI services to build intelligent features, the next critical consideration is scalability. Why? Because AI capabilities that work well in a sandbox often collapse under real-world conditions, when traffic spikes, data grows, or new markets demand different functionality.
So what exactly defines a scalable AI-powered application?
1. Elastic Performance
Scalability means your AI system can maintain low latency and high performance even as demand grows. This includes:
- Real-time inference that doesn’t break under concurrent users
- Load balancing across multiple model endpoints
- On-demand compute scaling using services like AWS SageMaker, Azure Machine Learning, or Google Vertex AI
2. Cost Efficiency at Scale
It’s easy to overspend if your cloud AI services aren’t optimized. Scalable apps use:
- Batch predictions where real-time isn’t needed
- Tiered storage for infrequently accessed training data
- Resource pooling to minimize idle compute costs
3. Maintainability
As your app evolves, so must your AI. Scalable apps:
- Support model versioning and rollback
- Automate retraining workflows
- Log predictions for continual performance monitoring

4. Extensibility
AI needs grow with the business. A scalable application allows:
- Plug-and-play support for new models (e.g., moving from sentiment analysis to topic modeling)
- Easy integration of new cloud AI services like translation, OCR, or time-series forecasting
5. Global Availability
Using cloud-native tools allows AI to serve users across geographies with minimal latency. Services like Azure’s Cognitive Services, AWS Comprehend, and Google Cloud Translation have multi-region support for this very reason.
Why It Matters
If your AI app fails under growth, it undermines user trust, drives up cloud bills, and delays feature delivery. That’s why scalability must be baked into your AI design, not added as an afterthought.

Find details on various use cases of Generative AI.
Now that you understand what makes an AI application scalable, the next step is selecting the right set of cloud AI services tailored to your use case. Not every model needs to be built from scratch, and not every service is a fit for real-time use. Let’s explore how to make the right technology choices to set your project up for success.
Choosing the Right Cloud AI Services for Your Architecture
Once scalability principles are in place, the next question every development team must ask is:
“Which cloud AI services should we use to build this AI-powered feature or application?”
The wrong decision can lead to ballooning costs, poor performance, or inflexible models. The right one can accelerate your time to market, reduce engineering effort, and scale seamlessly.
1. Start With the Use Case, Not the Tool
Cloud AI services work best when chosen based on the specific function they serve. Here’s how to think about it:
| Use Case | Recommended Cloud AI Services |
|---|---|
| Text analysis (sentiment, summarization) | Google Cloud Natural Language API, AWS Comprehend, Azure Text Analytics |
| Image processing or object detection | Google Cloud Vision, AWS Rekognition, Azure Computer Vision |
| Conversational AI or chatbots | Dialogflow (GCP), Amazon Lex, Azure Bot Service |
| Speech-to-text or translation | AWS Transcribe, Azure Speech Services, Google Cloud Speech-to-Text |
| Predictive analytics & custom models | SageMaker (AWS), Vertex AI (GCP), Azure Machine Learning |
Each platform offers pre-trained models, AutoML capabilities, and custom model pipelines, but the pricing, latency, and ease of integration vary.
2. Prebuilt APIs vs Custom Models
- Prebuilt APIs are best for rapid deployment. Use them when speed and standard functionality are your top priorities.
- AutoML services allow you to train models with minimal code and effort, ideal for teams with limited ML expertise.
- Custom models offer the highest flexibility and are required when you’re solving highly specific or proprietary problems.
Pro Tip: Cloud AI services often let you start with an API and gradually evolve to a custom model using the same ecosystem—this flexibility is crucial for scalability.
3. Evaluating Cloud AI Platforms
Each cloud provider has its strengths:
- Google Cloud AI Services: Known for ease of use, AutoML, and deep ML capabilities
- AWS AI Services: Offers massive scalability, reliability, and ecosystem breadth
- Azure AI Services: Strong in enterprise integration, hybrid cloud, and cognitive capabilities
Your choice should depend on:
- Latency requirements
- Data residency or compliance
- Integration with your existing tech stack
- Model deployment flexibility
- Pricing models (pay-as-you-go, reserved, etc.)
4. Interoperability and Vendor Lock-In
To build scalable applications, choose services that:
- Use open formats (ONNX, TensorFlow, PyTorch)
- Can export trained models outside the platform
- Offer multi-cloud or hybrid deployment options
Now that you’ve selected the right cloud AI services, it’s time to look at how to design an AI architecture that enables those services to perform at scale. This is where many projects stumble—but with the right patterns, you can future-proof your stack and deliver reliable AI at any scale.
Designing a Scalable AI Architecture
After selecting the right cloud AI services, the next challenge is designing the architecture. Without a solid foundation, even the most powerful AI services can lead to bottlenecks, instability, or rising costs.
Building an architecture that supports AI at scale involves more than just calling an API. It requires a thoughtful structure that ensures reliability, speed, and cost-efficiency as usage increases.

1. Decouple AI Workloads Using Microservices
A scalable architecture separates the AI components from the core application using microservices or containers. This allows each AI function to be developed, scaled, and updated independently. For example, sentiment analysis, image classification, and recommendation engines should operate as isolated services that communicate via internal APIs.
This approach aligns well with cloud AI services that are exposed through REST or gRPC interfaces, making them easy to plug into your microservice ecosystem.
2. Choose the Right Inference Strategy
Depending on the application type, you will need to decide between real-time and batch inference:
- Real-time inference is ideal for chatbots, recommendation engines, or fraud detection, where latency must be minimal. Use services with strong SLA guarantees and auto-scaling features.
- Batch inference is better for processing large volumes of data where time is less critical, such as customer segmentation or churn prediction. It is also more cost-effective.
Many cloud AI services allow both options. For example, AWS SageMaker supports asynchronous batch jobs, while GCP Vertex AI offers both online and batch predictions.
3. Serverless and Event-Driven Patterns
Integrating cloud AI services with serverless functions such as AWS Lambda, Google Cloud Functions, or Azure Functions allows you to build event-driven pipelines that scale automatically.
For instance, when a user uploads an image, a serverless function can trigger an AI service for classification and store the results in a database. This pattern is highly scalable and cost-effective since you only pay for what you use.
4. Load Balancing and Fault Tolerance
As AI services scale, load balancing ensures that incoming requests are distributed evenly across available compute resources. Use cloud-native tools like AWS Application Load Balancer, GCP Cloud Load Balancing, or Azure Front Door to handle AI traffic.
Ensure that retry logic and timeout settings are implemented correctly when invoking AI APIs. This protects your application from temporary service interruptions and guarantees reliability.
5. Multi-Region Deployment for Global Reach
If your users are spread across regions, latency can become a serious issue. Deploy your AI services closer to your users using multi-region availability options. Cloud AI services on major platforms allow you to deploy endpoints in North America, Europe, and the Asia-Pacific regions to reduce response times.
6. Centralized Monitoring and Logging
Scalable architectures include visibility into AI performance. Use cloud-native monitoring tools like AWS CloudWatch, GCP Operations Suite, or Azure Monitor to track:
- Model response time
- Failure rates
- Throughput per endpoint
Logging and tracing AI workflows help you detect bottlenecks and ensure long-term reliability.
With your architecture in place, the next step is to understand how to move from data to deployment. Let us now explore the complete AI development lifecycle in the cloud, from preparing datasets to deploying your first model into production.
End-to-End AI Workflow, From Data to Deployment
A scalable AI-powered application is not built on code alone. It depends on a comprehensive AI development lifecycle that begins with raw data and culminates in a deployed model serving real users. Cloud AI services provide the tools to manage this process with speed, efficiency, and consistency.
Here’s how to execute each stage of the AI workflow using cloud platforms like AWS, Azure, or Google Cloud.

1. Data Collection and Storage
Data is the fuel of AI. Start by collecting and storing structured or unstructured data in scalable, cloud-native systems:
- Use Amazon S3, Google Cloud Storage, or Azure Blob Storage for storing raw input
- Organize your data in buckets or folders with proper access controls and metadata
- For structured data, use BigQuery, Amazon Redshift, or Azure SQL Database
Cloud-based storage solutions integrate seamlessly with cloud AI services, ensuring high availability and fast data retrieval during model training.
2. Data Preprocessing and Feature Engineering
Before training a model, the data must be cleaned, transformed, and prepared. Use tools like:
- AWS Glue or Azure Data Factory for ETL pipelines
- Google DataPrep or Vertex AI Data Labeling for annotation
- Built-in Notebooks or Jupyter environments for custom feature engineering
Cloud platforms offer scalable compute and automation pipelines to speed up preprocessing, especially for large datasets.
3. Model Training Using Cloud AI Services
At this stage, decide whether to use AutoML or train a custom model.
- AutoML tools like Google AutoML, Azure AutoML, and SageMaker Autopilot allow quick model development without deep ML expertise
- For custom training, use TensorFlow, PyTorch, or scikit-learn on managed platforms such as Vertex AI Training, SageMaker Training Jobs, or Azure ML Designer
These cloud AI services handle infrastructure provisioning, GPU acceleration, logging, and checkpointing for you.
4. Model Evaluation and Validation
After training, validate your model using:
- Built-in evaluation tools in AutoML platforms
- Custom test sets with confusion matrices, ROC curves, and accuracy metrics
- Cross-validation and hyperparameter tuning with grid or random search techniques
Most cloud providers also support experiment tracking and comparison of multiple model runs.
5. Model Deployment
Once validated, deploy the model to an endpoint for production use:
- Use SageMaker Endpoints, Vertex AI Prediction, or Azure ML Online Endpoints
- Configure autoscaling to handle high-volume requests
- Set up A/B testing or shadow deployments to test performance in live environments
These endpoints support RESTful interfaces and integrate with your app backend, allowing your application to call predictions on demand.
6. Versioning and Model Registry
Maintain a registry of all trained models using:
- SageMaker Model Registry
- Vertex AI Model Registry
- Azure ML Model Management
These systems track versioning, metadata, lineage, and permissions, ensuring you can roll back or audit models as needed.
Now that your model is live and integrated into the application, the job isn’t over. In the next section, we will look at how to connect these AI models to your application layer, ensuring a smooth, real-time user experience while managing errors, scaling, and performance.
Integrating Cloud AI into Your Application Layer
A trained AI model has no real-world value until it is integrated into a working product. The integration phase is where AI meets users through a mobile app, web interface, dashboard, or automation workflow. The goal is to ensure smooth and secure interaction between your application and the selected cloud AI services.

1. Using Cloud AI APIs and SDKs
All major cloud platforms provide SDKs and client libraries to help developers connect AI features directly into the frontend or backend.
- Google Cloud AI SDKs support Python, Java, Node.js, and Go
- AWS AI SDKs are available through Boto3 (Python), AWS CLI, and Lambda extensions
- Azure AI SDKs include .NET, Python, and JavaScript support
Use these SDKs to:
- Send data securely for prediction
- Handle authentication and authorization via IAM or service principals
- Retrieve results and present them in your app interface
For serverless setups, you can also integrate with triggers (e.g., an uploaded image triggers classification using Cloud Functions or AWS Lambda).
2. Real-Time vs Asynchronous Integration
- For real-time predictions, your backend calls the cloud AI endpoint directly and returns results instantly (e.g., chatbot responses or fraud detection)
- For asynchronous workflows, you can queue the data (e.g., with Pub/Sub or SQS), process it using a worker, and store the result for later retrieval
Choose your method based on user experience expectations and cost implications. Many cloud AI services charge based on request volume and latency priority.
3. Error Handling and Fallbacks
Because cloud APIs rely on external endpoints, you must design for:
- Network failures
- Rate limits
- Timeout conditions
- Invalid inputs
Include retry logic with exponential backoff, input validation before API calls, and default fallback behaviors in the application.
4. Security and Compliance
Integration should follow strict security protocols:
- Secure communication using HTTPS
- Authentication with API keys, OAuth tokens, or service accounts
- Role-based access control to restrict who can invoke AI functions
- Audit logging of access and prediction data, especially for regulated industries
Ensure that any sensitive data sent to cloud AI services is anonymized or encrypted, especially in healthcare, finance, or government domains.
5. Monitoring Usage and Performance
Once deployed, track how the integration performs in the real world:
- Request volumes and failure rates
- Average response time and latency spikes
- Endpoint uptime and service health
Use tools like Stackdriver (GCP), AWS CloudWatch, or Azure Monitor to observe and alert based on key metrics.
With your application now connected to AI services and functioning in production, your next focus should be operational efficiency. The following section will explore how to apply MLOps practices to automate monitoring, retraining, and deployment across environments.
Operationalizing AI with MLOps Best Practices
Deploying a model is just the beginning. AI models degrade over time as data patterns shift, user behaviors change, or business requirements evolve. To maintain accuracy and reliability, organizations must adopt MLOps practices that automate model monitoring, retraining, and deployment. When combined with cloud AI services, MLOps ensures your AI application continues to deliver value at scale.
1. The Role of MLOps in Cloud AI Applications
MLOps, or Machine Learning Operations, is the equivalent of DevOps for AI. It focuses on:
- Automating the training and deployment lifecycle
- Managing version control for models
- Tracking experiments and performance metrics
- Ensuring models are reproducible and auditable
Cloud providers like AWS, Azure, and Google Cloud offer built-in MLOps tools such as SageMaker Pipelines, Azure ML Pipelines, and Vertex AI Pipelines. These services integrate seamlessly with training workflows, making them ideal for production-grade solutions.
2. Automating Model Retraining and Updates
Model drift can significantly reduce performance. To combat this, use cloud AI services to set up retraining triggers:
- Periodic retraining of jobs on new datasets
- Event-based retraining when accuracy falls below a threshold
- Automated pipeline runs triggered by new data ingestion
Automation ensures that your model evolves as your business grows.

3. Experiment Tracking and Model Versioning
Tools like MLflow, Vertex AI Experiments, or Azure ML help you track:
- Different training configurations
- Hyperparameter tuning outcomes
- Performance benchmarks
Versioned models can then be stored in a model registry, making it easy to roll back to a previous version if a new deployment underperforms.
4. Continuous Integration and Deployment for AI
Using CI/CD pipelines for AI ensures that any changes to your code, data, or models are automatically tested and deployed. For example:
- Train and validate models in staging environments
- You can use canary or A/B testing for gradual rollouts
- Monitor live performance before scaling to all users
Cloud AI services support this with native integrations into GitHub Actions, Jenkins, or other CI/CD tools.
5. Monitoring and Feedback Loops
Continuous monitoring is critical for detecting anomalies in predictions or performance:
- Log real-world predictions and compare with actual outcomes
- Set alerts for unusual behavior or data quality issues
- Implement feedback loops where user corrections are added back into the training set
With built-in monitoring tools like AWS CloudWatch or GCP AI Platform Monitoring, teams can track and respond to performance dips in near real time.
Now that your AI models are automated, versioned, and monitored, the next challenge is optimizing for cost and performance at scale. In the following section, we will explore strategies to ensure your cloud AI services remain efficient and budget-friendly as usage grows.
Optimizing Cost and Performance at Scale
As your AI application gains users, processes more data, and supports increasingly complex workloads, managing cost without compromising performance becomes a core priority. Fortunately, modern cloud AI services provide a wealth of tools, architectural patterns, and billing models that help teams build efficient, budget-conscious solutions.
1. Choose the Right Cloud AI Service Model
Cloud AI platforms typically offer three engagement models:
- Pre-trained APIs (e.g., text-to-speech, vision, NLP): Ideal for simple use cases with predictable cost and performance.
- Custom Model Training: More expensive, but essential for tailored AI behavior.
- Hybrid Models: Combine pre-trained and custom models for flexibility and cost balance.
To optimize, use pre-built models wherever sufficient, and reserve custom training for high-impact areas.
2. Use Serverless and Auto-scaling Features
Many cloud AI services now support serverless deployment or auto-scaling, such as:
- Google Cloud Run, Azure Container Apps, or AWS Lambda for lightweight inference
- Dynamic model scaling using Vertex AI Endpoints or SageMaker Inference Recommender
These allow you to scale up during high demand and scale down automatically during idle time, reducing infrastructure overhead.

3. Optimize Data Storage and Retrieval
Data used for training and prediction often makes up a large portion of your cloud costs. You can save by:
- Moving archived training data to cold storage tiers
- Using in-memory databases like Redis or Bigtable for real-time inference caching
- Compressing and batching inputs to reduce payload and processing time
4. Monitor Utilization and Cost Metrics
Cloud platforms offer granular monitoring dashboards:
- AWS Cost Explorer
- Azure Cost Management
- Google Cloud Billing Reports
Use these tools to:
- Set cost alerts
- Analyze usage by project or service
- Identify underutilized resources
5. Pay-as-you-go vs Reserved Pricing
If your AI workload is steady, consider reserved instances or committed use discounts on services like GPU compute, training jobs, or storage. Otherwise, stick to pay-as-you-go for spiky workloads.
6. Use Quantization and Distillation for Inference Efficiency
Reducing model size helps you deploy on smaller, cheaper instances. Popular methods:
- Model quantization: Reduce the precision of weights
- Model distillation: Train smaller models that mimic large ones
These strategies dramatically reduce inference time and compute cost without compromising much accuracy.
At this stage, you’ve built and optimized your scalable AI system. But how do you maintain growth, integrate securely, and ensure long-term success? In the final part, we’ll share key takeaways and how Emorphis can partner with you to build, deploy, and scale with confidence using cloud AI services.
Why Choose Emorphis for Cloud AI Services?
If you’re looking to accelerate your development and avoid missteps, partnering with a team that has deep technical expertise in cloud AI services is critical.
At Emorphis, we help you:
- Evaluate and select the right cloud AI platforms for your business needs.
- Design scalable architectures with modular AI components, secure APIs, and automation workflows.
- Integrate AI seamlessly into your software or enterprise system using best practices in DevOps, MLOps, and data orchestration.
- Optimize costs with smart deployment strategies and real-time monitoring.
- Scale responsibly with ethical AI implementation, explainability, and compliance.
We’ve supported healthcare companies, finance teams, manufacturing units, and SaaS platforms in deploying production-grade AI systems that are scalable, secure, and sustainable.
Ready to Build the Future?
If you’re seeking a technology partner to help you deliver intelligent applications with cloud AI services, we’re here to help. Let’s discuss your project vision and build the AI-powered future together.
Connect with the Emorphis expert solutions team to schedule a consultation and learn how we can transform your ideas into scalable AI applications using the power of cloud AI.
Final Thoughts
Throughout this guide, we’ve explored the foundational components of building scalable AI-powered applications, from architectural planning and choosing the right tools to integrating, optimizing, and managing your solution. At the core of every stage lies the transformative power of cloud AI services.
Whether you’re a startup experimenting with your first intelligent app or a large enterprise modernizing legacy systems, cloud AI services provide the agility, scalability, and intelligence needed to move fast and innovate securely.
Key Takeaways
- Start with architecture that supports modular, distributed AI capabilities.
- Use cloud-native tools from providers like AWS, Azure, and Google Cloud to simplify deployment, scaling, and security.
- Prioritize performance and cost optimization early with tools like model quantization, auto-scaling, serverless inference, and pay-as-you-go pricing.
- Keep evolving your solution with continuous integration of cloud AI services that provide new models, analytics features, and data management capabilities.



